【Python】将txt文件转换为html
本文共 1032 字,大约阅读时间需要 3 分钟。
分析txt文件内容,并按照以下规则及过滤器对文档添加对应的html标签
规则:- 标题是只包含一行的文本块,长度70个字符以内。以冒号(:)结束的文本块不属于标题。
- 题目是文档的第一个文本块,且满足标题的规则。
- 列表项是以连字符(-)打头的文本块。
- 列表以紧跟在非列表项文本块后面的列表项开头,以后面紧跟着非列表项文本块的列表项结束。
- 表格行是以竖线符号(|)打头的文本块,行内的列也是使用竖线分隔。
- 表格以紧跟在非表格行文本块后面的表格行开头,以后面紧跟着非表格行文本块的表格行结束。
使用正则表达式对文本块内容进行过滤,分别对尖括号内的内容,星号内的内容和网站及邮箱进行过滤
以下四个正则表达式对应过滤条件:r'\<(.+?)\>'r'\*(.+?)\*'r'(http(s){0,1}://[\.a-zA-z0-9/]+)'r'([\.a-zA-z0-9]+@[\.a-zA-z0-9]+[a-zA-z]+)' 各文本块之间用一个或多个空行间隔开,示例文档
Welcome to Foodly ,Inc.There π are the corporate web pages of *Foodly*.We hope you find your stay enjoyable,and that you will sample many of our product.A short history of th company......*Parsing HTML*Use the BeautifulSoup class to parse an HTML document. Here are some of the things that BeautifulSoup knows: - Some tags can be nested () and some can't (). - Table and list tags have a natural nesting order. For instance, tags go inside tags, not the other way around. - The contents of a
执行方式:
python3 markup.py < test_input.txt > test_input.html
test_input.html在谷歌上的显示效果如下
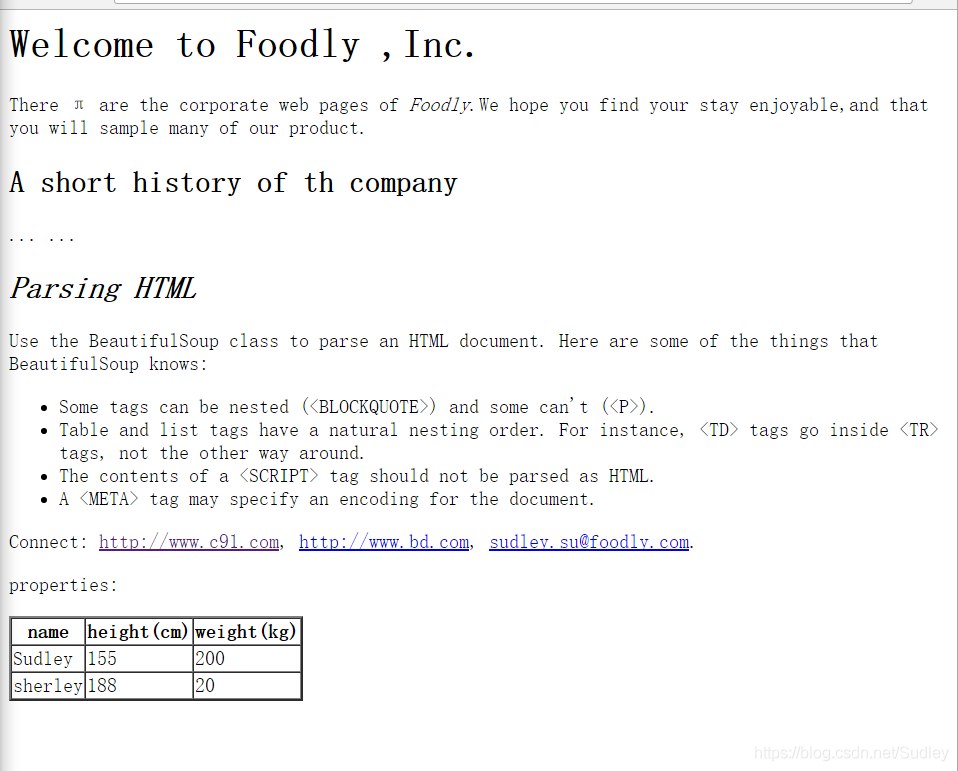 源码仓:
源码仓: 转载地址:http://euiti.baihongyu.com/
你可能感兴趣的文章
makefile中“-“符号的使用
查看>>
go语言如何从终端逐行读取数据?------用bufio包
查看>>
go的值类型和引用类型------重要的概念
查看>>
求二叉树中结点的最大值(所有结点的值都是正整数)
查看>>
用go的flag包来解析命令行参数
查看>>
来玩下go的http get
查看>>
队列和栈的本质区别
查看>>
matlab中inline的用法
查看>>
如何用matlab求函数的最值?
查看>>
Git从入门到放弃
查看>>
java8采用stream对集合的常用操作
查看>>
EasySwift/YXJOnePixelLine 极其方便的画出真正的一个像素的线
查看>>
Ubuntu系统上安装Nginx服务器的简单方法
查看>>
Ubuntu Linux系统下apt-get命令详解
查看>>
ubuntu 16.04 下重置 MySQL 5.7 的密码(忘记密码)
查看>>
Ubuntu Navicat for MySQL安装以及破解方案
查看>>
HTTPS那些事 用java实现HTTPS工作原理
查看>>
oracle函数trunc的使用
查看>>
MySQL 存储过程或者函数中传参数实现where id in(1,2,3,...)IN条件拼接
查看>>
java反编译
查看>>